
[논문리뷰] Medical Specialty Recommendations by an Artificial Intelligence Chatbot on a Smartphone: Development and Deployment
https://www.jmir.org/2021/5/e27460/
Medical Specialty Recommendations by an Artificial Intelligence Chatbot on a Smartphone: Development and Deployment
Introduction The COVID-19 pandemic has encouraged the development of telemedicine and the use of digital platforms []. In the field of remote medical support, various digital tools help minimize the number of face-to-face interactions between patients and
www.jmir.org
배경
COVID-19 대유행
으로 일상 활동이 제한되고 환자와 1차 의료 제공자 간의 접촉도 제한됨
이로 인해 환자를 적절한 의료 전문가에게 연결하는 것을 포함하여 적절한 1차 의료 서비스를 제공하기가 더 어려워짐
스마트폰과 호환되는 인공지능(AI) 챗봇이 환자의 증상을 분류하고 적절한 진료과목을 추천
한다면 가치 있는 솔루션이 될 수 있음
목적
비접촉식으로 적합한 진료과목을 추천하는 방법을 확립하기 위해
딥러닝 기반의 자연어처리(NLP) 파이프라인을 구축 하고
스마트폰에서 사용할 수 있는 AI 챗봇을 개발하는 것을 목표
방법
증상에 대한 정보가 포함된 118,008 문장(의료 전문 분야)을 수집하고 데이터 정제를 수행
최종적으로 본 연구를 위한 51,134 문장의 파이프라인을 구축
미리 훈련된 FastText 임베딩 레이어가 있거나 없는 4가지 LSTM(Long Short-Term Memory) 모델과
NLP용 변환기의 양방향 인코더 표현을 포함한 여러 딥 러닝 모델이 무작위로 선택된 테스트 데이터 세트.
모델의 성능은 정밀도, 재현율, F1-점수 및 수신자 작동 특성 곡선(AUC) 아래 영역을 기반으로 평가
환자가 이 전문 추천 시스템을 쉽게 사용할 수 있도록 AI 챗봇도 설계
AI 챗봇을 개발하기 위해 "Alpha"라는 오픈 소스 프레임워크 를 사용
이는 텍스트로 대화할 수 있는 프런트엔드 채팅 인터페이스와 데이터 수집을 처리하고 딥 러닝 모델로 데이터를 처리하고
데스크탑과 스마트폰 모두 호환되는 반응형 웹
결과
변환기 모델의 양방향 인코더 표현은 AUC 0.964 및 F1-점수 0.768로 최고의 성능
임베딩 벡터가 있는 LSTM 모델이 AUC 0.965 및 F1-점수 0.739
컴퓨팅 리소스의 한계와 스마트폰의 광범위한 가용성을 고려하여
AI 챗봇 서비스에 데이터 세트에서 훈련된 임베딩 벡터가 있는 LSTM 모델을 채택
또한 데스크톱과 스마트폰 모두에서 실행될 AI 챗봇의 알파 버전을 배포
데이터 수집 및 정리
NLP에 대한 딥 러닝 기반 모델의 감독 학습을 위해 단일 문장 증상 설명과 해당 의료 전문 분야가 모두 필요
웹 기반 건강 관리 플랫폼인 하이닥(Hidoc)이라는 한국 웹 사이트는
익명의 사용자(환자)를 4000명 이상의 전문의와 연결하여 의료 상담 서비스를 제공
모든 의료 전문가는 HiDoc 사용자에게 의료 상담을 제공하기 위해 승인을 위해 전문 면허를 제출(★)
사용자가 증상을 설명하는 HiDoc 게시물은 제목과 내용의 두 부분으로 구성
단일 문장 형식의 게시물 제목은 데이터 세트를 위해 수집
게시물에 응답한 전문의의 프로필에서 각 제목 문장에 해당하는 진료과목을 얻음
데이터 정리
첫째,
중복 및 누락된 데이터를 제거
둘째,
2단어 이하의 문장이나 진찰과 관련이 없는 문장 등
정확한 진료과 분류에 불충분한 모호한 문장은 수동으로 제외
셋째,
잘 훈련된 의사가 라벨을 잘못 지정한 데이터의 경우가 거의 없음
탐색적 데이터 분석
딥러닝 기반 NLP 모델을 개발하기 전에
데이터의 해석 가능한 특징을 추출하기 위해 탐색적 데이터 분석(EDA)을 수행
1) 데이터 분포를 평가하기 위해 각 클래스의 증상과 관련된 문장을 열거
또한 단어 표현을 위한 불용어(분류에 유용하지 않음) 및 키워드(분류에 유용함)와 같은 단어 목록을 만들기 위해
2) 가장 자주 사용되는 단어를 시각화
문장 길이는 각 모델에 대한 입력 시퀀스의 최대 길이를 확인하기 위해 결정(단어 수와 문자 수 모두의 측면에서)
딥러닝 모델 개발 (★)
장단기 기억 모델
임상 단어 표현은 NLP 모델의 성능에 중요한 요소임이 입증되었음
적절한 단어 표현을 추출하기 위해 불용어 목록의 단어를 제외한 명사에 대해
각 문장을 마이닝하고 각 명사가 키워드 목록에 포함된 경우 인덱스로 변환
Keras 라이브러리의 토크나이저를 사용하여 15,000개의 자주 나오는 명사를 해당 숫자로 대체
그 후 문장 길이의 일관성을 보장하기 위해 패딩 토큰이 문장에 추가
LSTM(Long Short-Term Memory) 모델의 입력으로
데이터 세트에서 훈련된 단어 임베딩 벡터 또는 FastText의 한국어 말뭉치로 사전 훈련된 단어 임베딩 벡터를 사용
임베딩 차원의 수는 2048로 설정되었습니다.
기본 LSTM 아키텍처로서 256셀 양방향 LSTM이 주의 계층이 추가되거나 추가되지 않은 모델의 백본 역할
또한, 정류된 선형 단위 함수가 있는 2개의 완전히 연결된 레이어가 적용되었고,
분류를 위해 softmax 함수가 있는 dense 레이어가 적용
우리는 4개의 서로 다른 LSTM 모델을 만듬
첫 번째는 데이터 세트에서 훈련된 임베딩 벡터가 있는 LSTM 모델
두 번째는 Bahdanau Attention LSTM 모델
대부분의 설정은 첫 번째 모델과 두 번째 모델에서 동일하지만 두 번째 모델은 양방향 LSTM 레이어 뒤에 256개의 셀이 있는 어텐션 레이어를 포함
세 번째 모델은 FastText 사전 훈련된 벡터가 있는 LSTM 모델
FastText의 사전 훈련된 벡터 데이터 세트를 로드하고 재구성하여 임베딩 매트릭스를 생성
이 행렬은 임베딩 레이어의 가중치로 사용
언급되지 않은 하이퍼파라미터는 첫 번째 LSTM 모델과 동일
마지막 변형은 FastText 벡터와 Bahdanau Attention을 모두 포함하는 LSTM 모델
FastText 사전 훈련된 벡터를 기반으로 하는 임베딩 계층과 Bahdanau 어텐션 계층이 있음
4개의 모델을 모두 컴파일할 때 범주형 교차 엔트로피와 Adam이 각각 손실 함수와 학습 최적화 도구로 적용
교육 과정에서는 평가 정확도를 보장하기 위해 10배 교차 검증을 수행
또한 과적합을 방지하기 위해 초기 중지 콜백 모니터링 유효성 검사 손실을 사용
배치 크기와 에포크 수는 각각 1000과 30으로 설정
트랜스포머 모델의 양방향 인코더 표현
BERT(Bidirectional Encoder Representation from Transformers) 모델은
질문 응답 및 자연어 추론과 같은 기타 NLP 작업뿐만 아니라
EMR을 사용하여 생의학 및 임상 엔티티 정규화에 대한 최첨단 성능을 달성
따라서 fine-tuning을 통한 문장 분류를 위해 BERT 모델을 사용
문장의 전처리를 위해 Huggingface의 오픈 소스 토크나이저를 적용
이 토크나이저는 예를 들어 특수 토큰([CLS]는 문장 시작, [SEP]은 문장 끝)을 추가하고
최대 시퀀스 길이로 패딩하고 어텐션 마스크를 생성하여 BERT 모델의 입력으로 사용할 각 문장을 인코딩
BERT 분류 모델은 완전히 연결된 계층과 상단에 softmax 기능이 있는 사전 훈련된 BERT 모델에서 구축
범주형 교차 엔트로피와 Adam 최적화 프로그램이 컴파일에 사용
LSTM 모델에서와 마찬가지로 통계 결과의 신뢰도를 높이기 위해 10배 교차 검증을 사용했고,
과적합을 피하기 위해 인내심 2로 "검증 손실"을 관찰하는 조기 중지 콜백을 설정
학습은 배치 크기가 100인 폴드당 30 에포크 동안 수행
평가
각 모델의 전체 데이터 세트에 대해 10-폴드 교차 검증을 수행한 다음
모델의 일반적인 성능을 평가하기 위해 10개의 서로 다른 폴드의 평균 점수를 계산
모델 성능은 정밀도, 재현율, F1 점수 및 AUC를 기반으로 평가
Wilcoxon 부호 순위 테스트는 그룹 간 차이의 중요성을 테스트하는 데 사용
AI 챗봇 개발
다음으로 환자가 챗봇 모델과 상호 작용할 수 있는 사용자 친화적인 애플리케이션을 개발
나이 등의 이유로 디지털 건강 격차를 만들지 않고 모두가 챗봇을 사용할 수 있도록 하고
정확한 의료 정보를 제공하는 것을 목표로 한국어의 격식 있는 어조를 채택
잘 설계된 챗봇은 개발자에게 민첩성을 제공하고 어떤 환경에서도 지속적으로 실행가능
이러한 요소를 고려하여 챗봇 아키텍처를 구축
일반적인 챗봇 아키텍처는 두 부분으로 단순화할 수 있음
첫 번째 부분은
기본 사용자 인터페이스를 보여주는 클라이언트 측
두 번째 부분은
대화 처리 논리와 NLP 모델을 포함하는 서버 측
우리는 오픈 소스 챗봇 프레임워크 Alpha를 사용하여 프로토타입 챗봇 클라이언트를 개발
"chat-bubble"을 포함하여 Alpha에 대한 다양한 챗봇 사용자 인터페이스 대안이 있지만 Alpha는 여러 가지 이유로 우수
일반적으로 오픈 소스 챗봇 사용자 인터페이스 프레임워크에는 메시지를 보내고 받는 기능만 있음
개발자 환경에서 테스트하거나 실행하기 어려움
Alpha 챗봇 프레임워크는 사용자 정의가 가능하고 완전한 챗봇 프레임워크
Alpha는 개발자가 지속적으로 변경되는 코드베이스를 빠르게 실행하고 테스트하는 데 도움이 될 수 있는
WebKit으로 사전 도킹되고 구축
또한 Alpha에는 데스크톱과 스마트폰 모두에서 사용할 수 있는 크로스 플랫폼 기능이 포함
신속한 개발을 위해 대상 사용자 기반에 맞게 Alpha의 클라이언트측 대화 논리를 수정
도구
자주 사용하는 단어는 "WordCloud"라는 Python 패키지를 사용하여
워드 클라우드로 시각화
한글 NLP용 Python 패키지인 KoNLPy를 단어 표현에 사용
Huggingface "Transformers" 패키지는
문장을 인코딩하고 BERT용 사전 훈련된 모델을 로드하는 데 사용
딥 러닝 모델을 구축하고 평가하기 위해 "Tensorflow" 프레임워크가 채택
머신러닝 연구를 위한 클라우드 서비스인 Google Colab이 본 연구에 사용
딥 러닝을 위한 다양한 라이브러리 및 프레임워크와 강력한 그래픽 처리 장치를 제공
R(버전 4.0.3, The R Foundation)을 사용하여 통계 분석을 수행
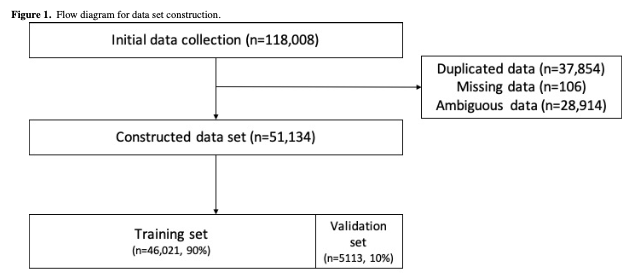
데이터 세트 구성
처음에 HiDoc의 26개 의료 전문 분야에 해당하는
환자의 증상을 논의한 118,008개의 문장을 수집하고
중복 데이터(n=37,854)와 누락 데이터(n=106)를 제거
모호한 문장(n=28,914)을 제외하고
26개의 전문과목 51,134개의 문장으로 구성된 최종 데이터셋을 구축(★)
데이터 세트는 10겹 교차 검증 동안
훈련 세트(n=66,021, 90%)와
검증 세트(n=5,113, 10%)로 무작위로 분할
전체 데이터 세트 구성 프로세스의 흐름도는 다음과 같다
EDA
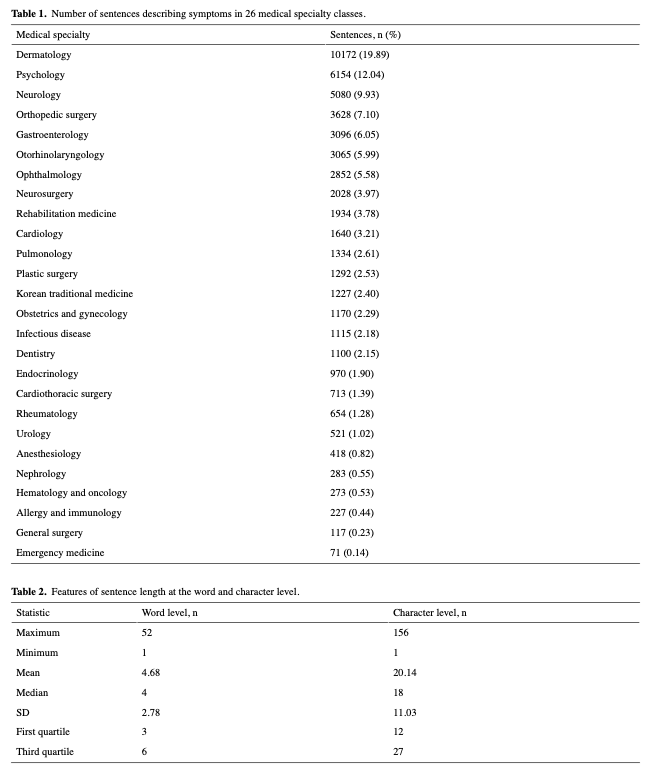
전공별로는 피부과(19.87%)가 가장 많았고, 심리학(12.04%), 신경과(9.93%), 정형외과(7.10%) 순이었다(표 1)
워드클라우드에서 일상적인 표현을 포함한 일부 빈도가 높은 단어가
데이터셋에서 우세한 것으로 나타나 빈도가 높은 단어 목록을 조사
또한 일부 유용한 통계 정보는 단어 및 문자 수준에서 식별할 수 있다(표 2)
EDA 결과는 AI 챗봇을 위한 최상의 NLP 모델을 식별하는 데
도움이 되는 3가지 중요한 아이디어를 제공
첫째,
데이터의 클래스 불균형으로 인해 F1-score는
모델을 정확하게 평가하고 비교하는 가장 중요한 척도로 간주되어야 함
둘째,
데이터 전처리 및 토큰화를 통해 모델의 성능을 향상시키기 위해
분류에 도움이 되지 않을 수 있는 "hello", "question", "ask"
와 같은 중지 단어 목록을 작성하기로 결정
의학적 표현(n=15,000)에서 자주 발견되는
"pain", "head", "sudden" 등의 키워드 목록
셋째,
두 수준의 문장 길이를 고려하여
각 모델에서 입력 레이어의 모양을 고정하기 위해
각 딥러닝 모델(LSTM 모델의 경우 10개, BERT 모델의 경우 30개)에 대한
입력 시퀀스의 최대 길이를 결정
딥러닝 모델 비교
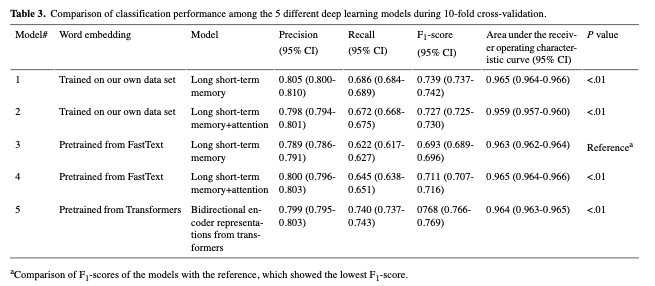
NLP에 대한 5가지 딥 러닝 모델에서 10배 교차 검증 후의 성능 결과는 표 3에 요약
BERT 모델이 최고의 성능을 보였고, LSTM 모델이 데이터 세트에서 훈련된 임베딩 벡터로 그 뒤를 이음
훈련된 모든 모델을 서버에 저장한 후, 우리는 서버가 데스크탑과 스마트폰 모두에서
요청을 처리할 수 있어야 하기 때문에 BERT 모델이 제한된 성능으로
GCP 계산 엔진에서 실행하기에는 너무 무겁다고 판단
따라서 우리는 두 번째로 좋은 분류 성능을 보인 데이터 세트에서
훈련된 임베딩 벡터와 함께 더 가벼운 LSTM 모델을 활용
AI 챗봇 배포
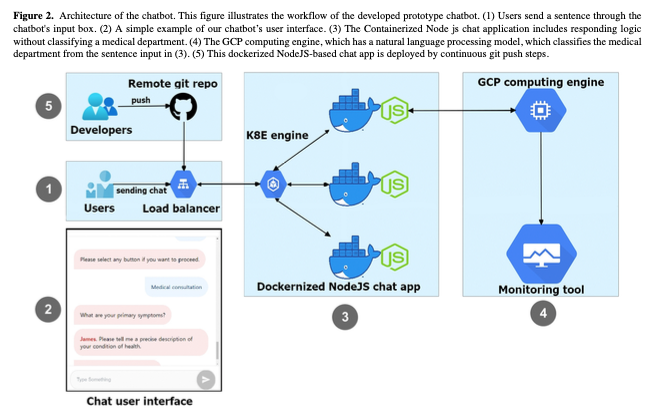
그림 2는 챗봇의 전체 아키텍처를 나타냄
완성된 챗봇 기능에 딥러닝 모델을 활용한 진료과 분류, 온라인 예약 시스템 링크, 의사 목록, 챗봇에 대한 간단한 소개를 제공하는 기본 거품형 버튼을 추가
사용자가 '진료상담'을 선택하면 챗봇이 사용자의 건강 상태를 설명하는 자연스러운 한국어 문장을 보내달라고 요청
문장은 배포된 서버로 전송되고 NLP 모델은 주어진 정보를 사용하여 의료 전문 분야를 분류
서버는 분류된 의료 전문 분야로 클라이언트에 응답
사용자의 장치는 클라이언트 측에서 생성된 완전한 문장을 보여줌
진료과목 결과에 따라 챗봇은 진료과목의 의사 일정을 제시하고 의사와의 약속을 도와주는 등의 서비스를 제공해야 하는지 사용자에게 묻는다
NLP 모델은 서버 측 e2-medium(vCPU 2개, 메모리 4GB) GCP 계산 엔진에 배포
Google Cloud Platform Kubernetes Engine(GKE)에 이 챗봇 프레임워크를 배포
이 프레임워크는 신속한 개발을 위해 Docker에 의해 컨테이너화되어 편리하게 결합
GKE의 Kubernetes에는 갑작스러운 챗봇 중단을 방지하기 위해
애플리케이션 트래픽을 분산하는 로드 밸런서 기능이 있다
개발 초기 단계에서 Kubernetes를 적용하면 개발자가
애플리케이션의 가동 시간, 성능 및 비용을 최적화하는 데 도움이 됨
또한 Kubernetes를 사용하여 자동화된 git 자동화를 적용하여 전송 속도를 높임
개발자가 수정된 코드를 로컬 컴퓨터에서 원격 GitHub 저장소로 푸시하면
GitHub는 GKE에 복제된 컨테이너화된 채팅 앱을 트리거
이 지속적인 배포 방법은 배포 서버에서 복잡하게 구성된 스크립트가 필요하지 않으므로 개발자의 부담을 덜어줌
클라우드 네이티브 환경에서 이 챗봇 프레임워크는 추가 기능을 쉽게 확장할 수 있는 토대를 마련
주요 결과
이 연구에서 BERT 모델은 의료 전문 분야의 최고의 classifier
그 다음은 데이터 세트에 대해 훈련된 임베딩 벡터가 있는 LSTM 모델
이 두 모델의 AUC는 각각 0.964 및 0.965이고 F1 점수는 0.768 및 0.739
그러나 이러한 값은
이전에 보고된 값(0.975-0.991의 AUC 및 0.845-0.870의 F1-점수)보다 낮다
그럼에도 불구하고 본 연구의 주요 결과는 다음과 같다
1) 우리가 아는 한, 이 연구는 의료 전문 분류를 위한
딥 러닝 기반 NLP 모델을 개발하기 위해
실제 환자의 증상에 대한 실제 설명을 사용한 최초의 연구
2) 향후 연구에 사용할 수 있는 한국어 데이터 세트를 구성
이 인공지능 챗봇은 환자가 자신의 현재 증상을 치료하기에
적합한 진료과목을 파악한 후 전 과정에서 대면 접촉 없이
해당 전문의와 진료 예약을 할 수 있도록 돕는다
기존의 딥러닝 기반 의학 문장 연구에서는
여러 목적에 최적화된 딥러닝 모델을 개발하여 제안
그러나 이러한 딥러닝 모델을 가지고도 웹 기반 서비스를 실용화하기 위해서는
많은 시간과 노력, 시행착오가 필요
또한 배포하기 전에 성능과 크기를 고려하여 딥 러닝 모델을 최종 선택
평가, 커뮤니케이션, 관리 및 기타 기능을 제공하는
최근에 개발된 다양한 웹 기반 의료 도구와 유사하게,
스마트폰 사용자 사이에서 AI 챗봇의 접근성에도 중점
코로나19 팬데믹으로 인해 원격의료 등 의료서비스에 인공지능 기술 활용이 늘어나면서
딥러닝 모델 개발부터 인공지능 챗봇 배치까지의 연구는 매우 중요해짐
실제 의료 환경에 빠르게 적용할 수 있다
대부분의 NLP 관련 의학 연구는 임상 기록 및 퇴원 기록과 같은 EMR을 사용
이러한 유형의 의학 텍스트는 "의사에게 친숙한" 단어로 구성됩니다. 즉, 의학 용어
따라서 이러한 연구에서는 환자가 호소하는 불만 표현을
모델의 입력으로 사용하기 전에 적절한 방식으로 변환해야 함
AI 챗봇의 입력에도 적합하지 않음
그러나 본 연구에서 딥러닝 기반 NLP 모델 개발을 위해 구축하여 사용한 데이터셋은
현재 운영 중인 웹 기반 헬스케어 플랫에서 가져온 '환자 친화적' 단어들로 구성
이 데이터 세트를 사용하여 환자가 쉽고 편리하게 상호 작용할 수 있는 AI 챗봇을 개발하는 데 도움이 됨
또한, 언어마다 NLP 연구에 큰 영향을 미칠 수 있는 특성이 다르기 때문에
진단, 치료 및 예측을 포함하여
추가 NLP 기반 의학 연구에 이 한국어 의학 언어 데이터 세트가 유용할 수 있다
제한 사항
이 연구의 한 가지 한계는 NLP 모델 개발에 사용된 데이터 세트의 코퍼스가 특정 웹 사이트에서 얻은 것
첫째,
인구통계학적으로 웹사이트에 접속한 대부분의 HiDoc 사용자는 65세 미만
그들은 또한 감별 진단하기에 충분히 복잡하지 않고
다른 사람들과 쉽게 공유할 수 있을 만큼 민감하지 않은 비응급 증상을 가짐
이것은 증상 관련 문장의 가장 큰 비율이 피부과와 관련이 있고
그 다음이 심리학과 관련된 이유를 설명가능
둘째,
원격 커뮤니케이션을 위해 문자 메시지를 사용하는 현재의 챗봇은 노인들에게 불편할 수 있음
이처럼 취약하고 지속적으로 증가하는 인구의 요구를 간과하지 않기 위해서는
음성 기반 커뮤니케이션과 같은 추가적인 커뮤니케이션 전략이 필요.
최근 한 연구에서는 스마트 스피커가 한국 노인들에게
AI 기반 디지털 건강 시스템을 도입하는 데 효과적인 솔루션이라고 보고
따라서 스마트 스피커를 비롯한 다른 AI 기반 기술에 대한 추가 연구가 필요
셋째,
단일종합병원 체계를 바탕으로 26개 전문과목으로 분류
이는 모델의 일반화 가능성에 영향을 미칠 수 있다
다른 의료 시설에 존재하는 일부 의료 전문 분야가 누락되었을 수 있다.
넷째,
데이터 및 컴퓨팅 리소스의 양이나 품질과 같은 연구의 일부 측면이 제한되었을 수 있다
분류를 위한 딥 러닝 모델의 성능을 개선하기 위해
BERT와 같은 대규모 모델에
고품질 데이터의 추가
대규모 컬렉션과 비용이 많이 드는 최신 고성능 계산 엔진을
사용할 수 있다
다섯째,
심층 학습 모델의 해석 가능성과 관련하여
지원 벡터 머신 및 나이브 베이즈 분류기와 같은
얕은 학습 모델의 사용이 추가 연구를 위해 제안될 수 있다
여섯째,
우리의 AI 챗봇 서비스가
실제 환경에서 올바른 진료과목을
얼마나 잘 선택하는지 평가하기 위한 임상시험이 필요
결론
환자에게 적합한 진료과목을 추천하는 스마트폰 호환 AI 챗봇 서비스의 가능성을 보여줌
딥 러닝 기반 NLP 모델을 개발하고 새로운 AI 챗봇을 배포
이러한 비대면 의료서비스는 코로나19 팬데믹의 어려움을 극복하기 위한 유망한 전략