깃허브 : https://github.com/JsuccessJ/youtube_ranking_system
GitHub - JsuccessJ/youtube_ranking_system: Recommending What Video to Watch Next: A Multitask Ranking System(2019 RecSys)
Recommending What Video to Watch Next: A Multitask Ranking System(2019 RecSys) - JsuccessJ/youtube_ranking_system
github.com
1. Introduction
유튜브(YouTube)와 같은 대규모 비디오 추천 시스템에서 “다음에 시청할 영상을 추천”하는 문제를 다룹니다. 기존의 대규모 추천 시스템은 다음과 같은 어려움이 있습니다.
- multi-objective의 존재
- 클릭, 시청 시간, 좋아요(만족도), 비추천(불만족도) 등 여러 지표를 동시에 최적화해야 함.
- 여러 지표가 상충(conflict)할 수 있어, 이를 단일 모델로 처리하기 어렵다는 문제.
- Implicit feedback의 bias
- 사용자가 실제로 어떤 동영상을 좋아하는지(“진짜” 유틸리티)와 달리, 노출 순서(위치) 등에 의해 편향된 데이터를 얻게 됨.
- 예: 추천 목록 상단에 있는 영상은 더 많이 클릭됨(‘Position Bias’).
이 문제를 해결하기 위해 논문에서는 Multi-objective 최적화를 수행할 수 있는 신경망 모델을 제안하고, 편향을 보정하기 위한 기법을 함께 소개합니다. 특히, MMoE(Multi-gate Mixture-of-Experts) 기반의 확장된 Wide & Deep 구조를 활용함으로써, 여러 목표를 동시에 최적화하면서 편향을 완화하는 방법론을 제시합니다.
2. Related Work
2.1 산업용 추천 시스템
- 실제 대규모 추천 시스템은 two-stage (후보 생성 → 랭킹)을 주로 사용합니다.
- 후보 생성(Candidate Generation): 수많은 아이템 중 수백~수천 개의 후보 아이템만 뽑아냄.
- 랭킹(Ranking): 후보 아이템 각각에 대해 점수를 매기고 최종적으로 상위권에 노출할 아이템을 결정.
- 규모가 매우 크므로, 시간/자원 제약을 고려해 빠르면서도 정교한 모델을 사용해야 함.
- 관련 예시: 구글, 페이스북, 트위터, 핀터레스트 등에서 확립된 대규모 추천 기술들이 있음.
2.2 다중 목표 학습(Multi-objective / Multi-task)
- 추천 시스템은 여러 사용자 행동(클릭, 시청 시간, 좋아요 등)을 동시에 예측해야 하므로, Multi-objective 최적화가 필연적임.
- 전통적으로 Shared-bottom 방식(하나의 하단 레이어를 공유)이 흔히 쓰였지만, 목표끼리의 충돌이 발생할 때 성능 저하 가능성이 있음.
- MMoE(Multi-gate Mixture-of-Experts)(2018 SIGKDD)는 여러 experts와 gate network를 활용해, task별로 필요에 따라 전문가를 다르게 활용할 수 있어 Multi-objective 최적화에 효과적임. [MMoE 참고 게시글]
2.3 편향(Selection Bias) 모델링 (2018 SIGKDD 이후 추가된 내용)
- 랭킹 시스템은 “사용자가 노출된 아이템 중에서 행한 행동(클릭, 좋아요 등)” 데이터를 학습에 활용.
- 노출 순서(position) 등의 이유로, 클릭 확률이 왜곡되거나 편향된 데이터를 얻게 됨. 이를 “Position Bias”라고 함.
- 과거에는 위치(feature) 정보를 모델에 직접 넣은 뒤, 서빙 시 이를 제거하거나(또는 고정) 하는 방식이 많이 쓰였음.
- 혹은 별도의 Propensity Score(편향 보정 계수)를 추정해 보정하기도 하나, 대규모 시스템에서 매번 랜덤화 실험을 하거나 복잡한 수식을 푸는 것은 부담이 큼.
- 논문에서는 Wide & Deep 모델(2016 google) 구조를 이용해 Position Bias를 별도 타워(shallow tower)에서 학습 후, 최종 예측값에 bias term을 반영하는 기법을 제안함.
3. Problem Description
“현재 시청 중인 동영상(쿼리)”가 주어졌을 때, 그 다음으로 사용자가 시청할만한 적합한 동영상을 추천하는 랭킹 문제를 정의
- 2단계 구성:
- 후보 생성: 수많은 비디오 중 협업 필터링(co-occurrence, MF 등) 또는 콘텐츠 분석(동영상 제목, 해시태그, 시청자 유사도 등)을 통해 수백 개의 후보군 생성.
- 랭킹: 후보 비디오 각각에 대해서, 거대 신경망 모델로 점수를 산출하여 정렬.
- 학습 목표(Multi-objective)
- Engagement: 클릭, 시청 시간 등 사용자가 실제로 얼마나 콘텐츠에 참여하는가.
- Satisfaction: 좋아요, 별점, 비추천 등 사용자가 얼마나 만족(또는 불만족)하는가.
- Implicit feedback 기반
- explicit 평점(별점)이 아니라, 클릭 로그, 시청 시간 등 "implicit" 사용자 행동 데이터가 주로 활용됨.
- 편향을 내포할 수 있기 때문에 주의해야 하며, 논문에서는 이 부분을 별도 구조(shallow tower)로 학습해 보정함.
4. Model Architecture
"Multi-objective ranking"과 "Position Bias mitigation"을 통합한 모델 구조 제안.
4.1 전체 시스템 개요

- Wide & Deep 모델을 기본 틀로 하여, MMoE Layer를 통해 Multi-objective를 처리하고, Shallow Tower로 선택 편향(주로 Position Bias)을 보정합니다.
- 전체 파이프라인:
- 입력: Bias features // query & candidate video features // User & context features // Dense Features(연속형 numerical data로 예상)
- 신경망을 통해 다중 출력(클릭 확률, 시청 시간, 좋아요 확률 등)을 예측.
- 최종 점수: 여러 예측값을 가중 합·곱 등의 방식으로 합성하여 최종 랭킹 점수로 활용.
입력 데이터 처리
def forward(self, categorical_x, numerical_x):
# categorical_x: (batch_size, categorical_field_dims) - 범주형 특성
# numerical_x: (batch_size, numerical_num) - 수치형 특성
특성 임베딩 및 전처리
# 범주형 특성 임베딩
categorical_emb = self.embedding(categorical_x) # (batch_size, field_num, embed_dim)
# 수치형 특성 변환
numerical_emb = self.numerical_layer(numerical_x).unsqueeze(1) # (batch_size, 1, embed_dim)
# 모든 임베딩을 하나의 벡터로 결합
emb = torch.cat([categorical_emb, numerical_emb], 1).view(-1, self.embed_output_dim)
# (batch_size, (field_num+1)*embed_dim)
SideTower
# Wide 부분 - 선택 편향 모델링
selection_bias_logit = self.side_tower(emb) # (batch_size,)
Shared Bottom Layer
# 공유 특성 추출 (Deep 부분 시작)
shared_features = self.shared_bottom(emb) # (batch_size, shared_bottom_output_dim)
Experts Layer
# 여러 전문가 모델의 출력 계산
expert_outputs = torch.stack([expert(shared_features) for expert in self.experts], dim=1)
# (batch_size, expert_num, bottom_mlp_dims[-1])
Task Specific
게이팅 네트워크
# 게이트 값 계산
gate_values = self.gates[i](shared_features).unsqueeze(1) # (batch_size, 1, expert_num)
특성 결합
# 게이트 값과 전문가 출력 결합
combined_features = torch.bmm(gate_values, expert_outputs).squeeze(1) # (batch_size, bottom_mlp_dims[-1])
타워 네트워크
# 타워 네트워크 통과 및 sigmoid 적용
task_output = torch.sigmoid(self.towers[i](combined_features).squeeze(1)) # (batch_size,)
selection bias 보정
# Wide & Deep 아키텍처 적용 (참여도 태스크에만)
if self.use_wide_and_deep and i == 0:
bias_weight = torch.sigmoid(selection_bias_logit)
task_output = task_output * (1 - bias_weight) + bias_weight * 0.5
최종 랭킹 스코어 계산
# 소프트맥스 가중치 계산
normalized_weights = torch.nn.functional.softmax(self.ranking_weight, dim=0) # (task_num,)
# 최종 랭킹 스코어 계산 (가중 조합)
ranking_score = torch.zeros_like(task_outputs[0]) # (batch_size,)
for i in range(self.task_num):
ranking_score += normalized_weights[i] * task_outputs[i]
벡터 Shape 예시
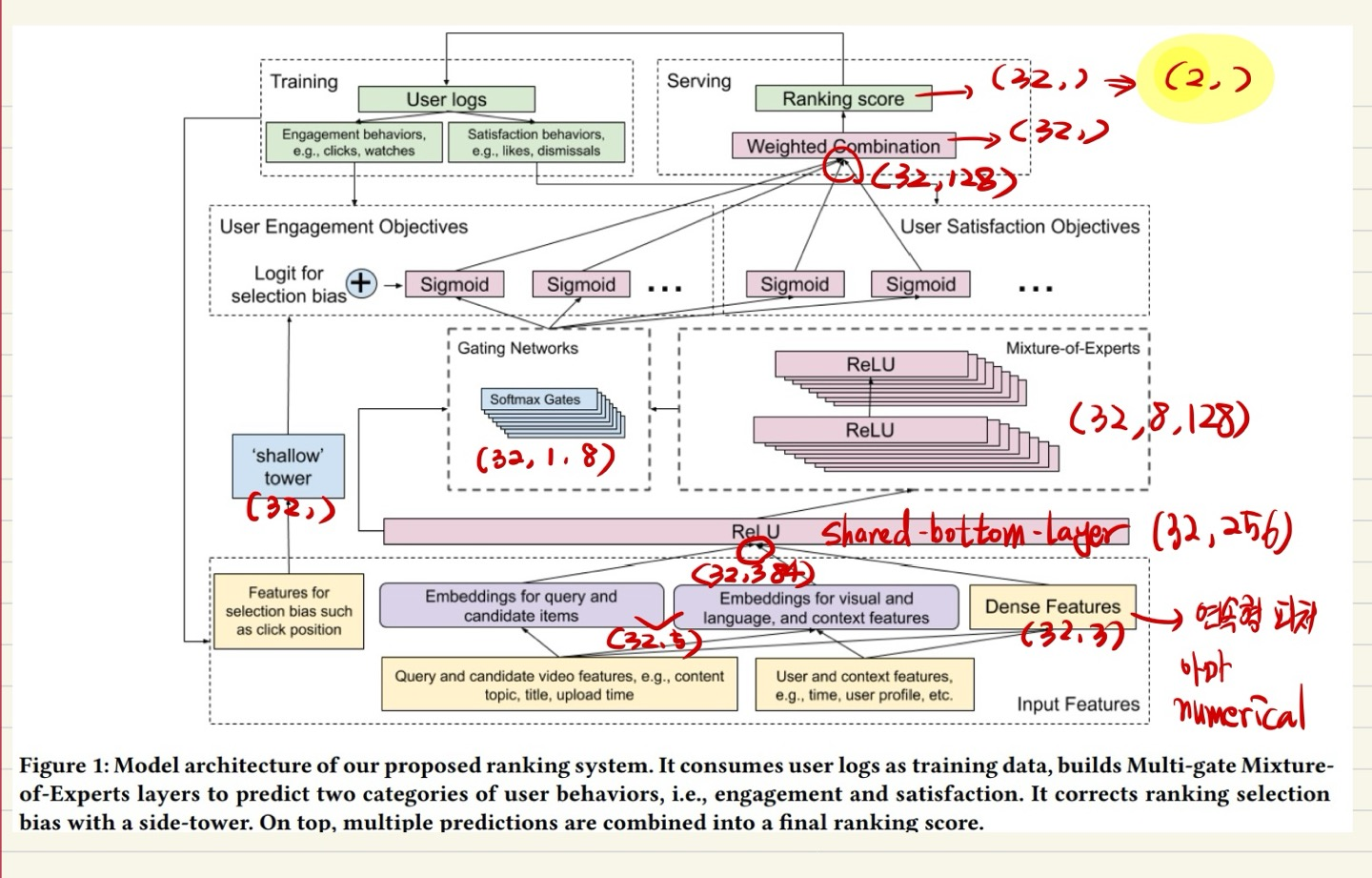
4.2 MMoE Structure
(1) Shared-bottom 방식의 한계
- 전통적으로 하나의 공통(hidden) 레이어를 공유하고, 상위 층에서만 분기하여 목표별로 출력하는 방식을 사용함.
- 목표 간 상충(conflict)이 있을 때, 서로가 파라미터를 공유하면서 제약이 생기는 단점이 존재.
(2) Mixture-of-Experts (MoE) 기법
- 여러 개의 Expert 네트워크를 두고, 각각 다른 부분공간이나 기능을 학습하도록 유도.
- Gating 네트워크는 입력을 받아 각 Expert를 어느 정도 가중치로 사용할지 결정(softmax 기반).
(3) MMoE(Multi-gate Mixture-of-Experts)
- Multi-objective 학습에 최적화된 형태의 MoE.
- 각 Task마다 게이트 네트워크를 하나씩 두고, 공유된 다수 Expert에 대해 목표별로 다른 softmax 가중을 적용.
- 예: 목표1(클릭)은 Expert1, Expert3을 주로 사용하고, 목표2(시청 시간)는 Expert2, Expert3을 집중적으로 사용할 수 있음.
- 이렇게 함으로써 목표 간 상충을 최소화하면서 필요한 부분의 표현은 공유할 수 있음.
논문에서는 이 MMoE 레이어를 기존 Wide & Deep 모델의 일부(Shared Layer 부분)에 삽입하여, 효율적으로 Multi-objective를 처리(추가 파라미터를 무작정 늘리지 않고, 효율적 공유).
4.3 Position Bias, Selection Bias 보정
암묵적 피드백(implicit feedback)에서는 “어떤 동영상이 상단에 노출되었기에 클릭률이 올라간 것인지, 정말 사용자 취향이라 클릭한 것인지”를 구별하기 어렵다. 논문에서는 이를 간단히 Position Bias의 예시로 설명하고, Shallow Tower를 추가하여 해결.
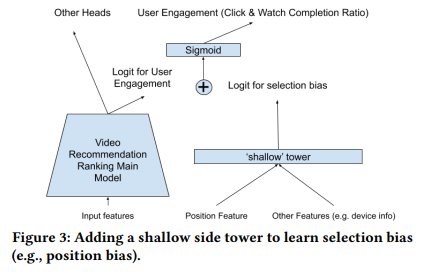
(1) Shallow Tower 구조
- Wide & Deep 모델에서 Wide 파트에 해당하는 얕은 신경망(shallow network)을 추가로 둠.
- 이 타워에는 편향을 일으키는 주요 피처(예: 노출 위치, 디바이스, 노출 방식 등)를 입력값으로 사용.
- 랭킹을 위한 메인 DNN과는 별도의 경로로 bias를 추정하고, 최종 예측값에 “bias term”을 더해 주는 형태.
(2) 학습 시와 서빙 시의 차이
- 학습 단계:
- 실제 로그 데이터에 있는 position 등 편향 관련 특징을 그대로 입력 받아, bias logit을 학습.
- label(클릭, 시청 시간 등)과의 차이를 최소화하면서, 편향을 최적화된 형태로 학습하게 됨.
- 서빙(실서비스) 단계:
- 실제 추천 시에는 position 등이 결정되지 않았거나, 혹은 의도적으로 “미싱 값”으로 설정해 편향을 제거.
- 따라서 해당 shallow tower는 주로 “편향 보정”의 상수 또는 특정 값으로 작동하여, 사용자가 실제로 좋아할 만한 순서로 재정렬해 주는 효과가 있음.
이 기법은 Position Bias 외에도, “현재 시스템의 추천 성능” 자체가 만들어낸 선택 편향을 어느 정도 완화해 줄 수 있는 장점이 있습니다.
5. Experiment Results
논문에서는 실제 YouTube 서비스 환경에서의 대규모 실험(오프라인 및 온라인 A/B 테스트)을 통해 모델 성능을 검증하였습니다.
5.1 실험 세팅
- 데이터: YouTube 로그에서 추출한 암묵적 피드백(클릭, 시청 시간, 좋아요 등).
- 모델: 다음과 같은 방식으로 학습 모델을 비교.
- Shared-bottom DNN
- MMoE(전문가 4개, 8개 등)
- Position Bias 보정 여부(Shallow Tower vs. 단순 인풋 vs. Adversarial Loss 등)
- 지표:
- Engagement 측면: 클릭률, 총 시청 시간 등
- Satisfaction 측면: 좋아요 확률, 사용자 만족도 설문 결과 등
- 추가로, 계산량 대비 성능 개선 폭도 고려(유튜브는 대규모 트래픽 처리 필요).
5.2 Multi-objective 최적화 성능
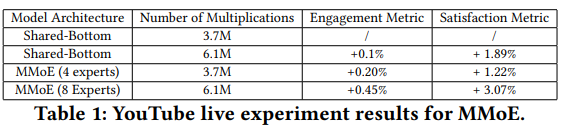
- Baseline 으로 Shared-Bottom 형태 + 공평한 설계 위해 Multiplication 동등하게..
- MMoE 구조가 기존 Shared-bottom 대비 Engagement와 Satisfaction 모두 유의미하게 향상.
- Expert 수(4개 vs. 8개)를 늘리면 학습 능력이 커지지만, 그만큼 연산량이 증가.
- 실제 A/B 테스트에서도 시청 시간이 늘고, 만족도 역시 개선되었다는 결과가 보고됨.
5.3 Position Bias 보정 효과
- 별도의 Shallow Tower 없이 position 피처만 인풋에 직접 넣는 방식은 제한적 개선 혹은 성능 미미.
- Adversarial Loss로 position 예측을 억제하는 방식은 복잡도 대비 큰 효과가 없었음.
- Shallow Tower 방식이 가장 안정적이며 실질적인 A/B 테스트에서 시청 지표가 상승함.
6. Discussion
6.1 뉴럴 네트워크 모델 아키텍처에 대한 통찰 (5.4.1 Neural Network Model Architecture)
- 다양한 도메인·모달리티를 아우르는 것이 쉽지 않음
- 텍스트(제목·설명), 썸네일 이미지, 오디오 특성, 사용자 프로필 등 여러 소스를 단일 모델이 모두 다루어야 함.
- 자연어 처리나 컴퓨터 비전 등의 모델 아키텍처가 바로 추천 시스템에 적용되기엔, 데이터 스케일이나 온라인 서빙 제약 등에서 문제가 발생.
- 분산 학습 및 대규모 학습의 복잡성
- 사용자와 아이템이 수십억 규모이므로, 파라미터 업데이트와 임베딩 학습에도 고비용이 듦.
- 거대한 NN 모델을 분산 학습할 때 발생하는 DNN 안정성 이슈(예: ReLU Dead, Gradient Explosion 등)를 관리해야 함.
6.2 성능과 효율성 사이의 균형 (5.4.2 Tradeoff between Effectiveness and Efficiency)
- 복잡한 모델이 오프라인 성능을 높일 수 있어도, 온라인 서빙 비용(추론 속도, 자원 사용)이 너무 커지면 문제가 됨.
- 온라인 추천에서 응답 지연(latency)은 사용자 경험과 직결되므로, 지나치게 무거운 모델은 실제 적용이 어려움.
- 결과적으로 “간단하지만 효과적인 모델”이 추천 시스템에서는 더욱 실용적일 수 있음.
6.3 훈련 데이터 편향 이슈 (5.4.3 Biases in Training Data)
- 논문에서 주요하게 다룬 ‘Position Bias’ 외에도, 사용자 로그에는 다양한 형태의 편향(Selection Bias, 시스템 노출 편향 등)이 함축되어 있음.
- 사용자의 실제 의도와는 무관하게 상단 노출된 아이템이 과도하게 클릭될 수 있음.
- 편향을 완전히 제거하는 것은 쉽지 않고, Unknown 형태의 편향이 여전히 학습에 영향을 줄 수 있음.
6.4 평가(Evaluation)의 어려움 (5.4.4 Evaluation Challenge)
- 오프라인 지표(AUC, MSE 등)로 본 모델 예측 성능이 온라인(A/B 테스트) 결과와 항상 일치하지 않음.
- 예: 오프라인에서 A 모델이 좋다고 나와도, 실제 실험하면 B 모델이 사용자 만족도를 더 높일 수도 있음.
- 추천 시스템에서는 온라인 A/B 테스트가 궁극적인 판단 기준이지만, 이를 빈번하게 돌리는 것은 비용이 매우 큼.
- 따라서 모델의 일반화 성능을 최대화하고, 오프라인-온라인 지표 간의 괴리를 줄이는 것이 목표.
6.5 향후 연구 방향 (5.4.5 Future Directions)
- 다중 목표 구조 고도화
- MMoE 이후에도, 모델 안정성(분산 학습 환경)·표현력을 동시에 잡는 새로운 방법이 필요.
- 자동 편향 학습·보정
- Position Bias 외에도 “알려지지 않은” 편향을 자동 식별·보정하는 체계가 요구됨.
- 모델 압축(Model Compression)
- Serving 비용을 줄이기 위해 Knowledge Distillation나 Quantization 등으로 거대 NN을 가볍게 만드는 작업도 중요.
7. Conclusion
본 논문은 대규모 비디오 공유 플랫폼(YouTube)에서 다음 시청 영상 추천 문제를 다루면서, Multi-objective 최적화와 선택 편향 보정이라는 두 가지 핵심 과제를 해결할 수 있는 MMoE + Wide & Deep 아키텍처를 제안하였습니다.
- MMoE를 활용하여, 클릭/시청 시간/좋아요/비추천 등 서로 다른 지표들을 하나의 모델 안에서 충돌 없이 효율적으로 학습.
- Shallow Tower(Wide 파트)를 통해 암묵적 피드백에 내재된 Position Bias 등 선택 편향을 보정.
- 실제 A/B 테스트에서 Engagement와 Satisfaction 모두 의미 있는 개선을 달성.
향후 과제
- 더 정교한 Multi-objective 구조: 다른 형태의 soft-parameter 공유 기법, gating 안정성 강화 등 추가 탐색.
- 자동 편향 인식: 단순 position 외에도, 노출 빈도/추천 맥락 등 다양한 편향을 자동으로 인식해 보정.
- 모델 압축: MMoE 모델이 커질수록 추론 속도가 느려지므로, 실제 서빙에 부담이 없는 효율적인 모델 경량화 기법.
Questions
Q1. Serving 이란 무엇인가?
- 정의
논문에서 “서빙(Serving)”은 모델을 실제 서비스 환경에서 실시간 추론(Inference)을 수행하는 과정을 말한다. 즉, 학습(Training)된 모델이 프로덕션(Production) 환경에서 사용자에게 추천 결과를 제공할 때, 새로운 입력(사용자/컨텍스트/아이템 정보 등)이 들어오면 모델이 이를 기반으로 점수를 산출하고, 최종 랭킹에 반영하는 단계. - 학습(Training)과 서빙(Serving)의 차이
- 학습 단계: 방대한 과거 로그(사용자 클릭·시청 기록 등)를 이용해 모델 파라미터를 업데이트. position(노출 순위), 노출 빈도, 디바이스 등 다양한 특징을 포함해 모델이 “과거 상황”을 최대한 잘 설명하도록 최적화.
- 서빙 단계: 실제 사용자가 현재 유튜브 영상을 보고 있고, 추천 탭에 들어왔다는 트리거가 생기면, 후보 아이템들에 대해 학습된 모델을 실시간으로 추론하여 상위 N개 영상을 노출.
- Position Bias 보정 관련
- 논문에서는 훈련 시 position 같은 편향 유발 피처를 모델에 주어 ‘bias term’을 학습하지만, 실제 서빙 시에는 해당 피처를 고정값(혹은 미싱값)으로 둬서 편향을 보정.
- 이러한 처리 방식은 “학습 시의 데이터 편향을 최대한 모델이 인지하게 하되, 서빙 시에는 모델이 그 편향에 덜 의존하게 만드는” 전략.
정리하자면, “서빙시”란 실제 온라인 서비스 환경에서 사용자 요청마다 모델이 추론하여 추천을 제공하는 단계를 의미.
Q2. 2018년 SIGKDD 논문(MMoE)과의 차이점
- 이전 논문:
- “Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts” (SIGKDD 2018)
- 여기서는 다중 목표(multi-task) 학습을 위해 MMoE(여러 Expert + 목표별 Gating) 구조를 제안.
- 즉, 'MMoE라는 소프트 파라미터 공유 기법이 다중 목표 성능을 향상시킨다'는 이론적/실험적 근거를 제시한 논문.
- 이번 논문:
- 실제 비디오 랭킹 문제에 특화
- YouTube ‘다음 시청 추천’이라는 매우 구체적이고 대규모인 산업 현장에 적용
- Engagement(시청 시간·클릭)과 Satisfaction(좋아요·평점) 등의 멀티목표 랭킹에 MMoE를 적용하여 A/B 테스트로 검증
- Selection Bias, 특히 Position Bias 보정
- MMoE만으로는 해결하기 어려운 문제(추천 목록 상단 노출이 클릭 확률을 과도하게 높이는 현상)를 Wide & Deep 구조의 “Shallow Tower”로 보정
- 이는 기존 MMoE 논문에서 다루지 않은, “실제 사용자 행동 로그가 가진 편향을 어떻게 학습 단계에서 보정하느냐”라는 추가 난제를 풀어낸 것
- 유튜브라는 초대형 스케일의 Live 실험
- 논문에서는 실제 유튜브 사용자 대상 실험(A/B Test)으로 성능 향상을 증명
- 실제 비디오 랭킹 문제에 특화
결론적으로, SIGKDD 2018의 MMoE 논문을 “다중 목표 신경망 구조”의 토대로 삼되,
- (a) YouTube 랭킹에 적합한 설계(Engagement & Satisfaction 이원화),
- (b) Shallow Tower로 Position Bias 보정 기법,
- (c) 대규모 온라인 실험 결과 보고
이 세 가지가 이번 논문만의 주요 추가/차별점이라 볼 수 있다.
Q3. Table 1의 “Number of Multiplications”란?
- 논문에서 Table 1(YouTube live experiment results for MMoE)은 모델 구조별로 “Number of Multiplications”와 “Engagement Metric / Satisfaction Metric 결과”를 제시.
- 의미
- “Number of Multiplications”는 “해당 모델이 추론(Forward pass) 시 수행해야 하는 곱셈 연산 수”를 대략적으로 나타낸 값.
- 논문에서는 곱셈(Multiply) 연산량이 주요 계산 비용을 결정한다고 보고, 이를 모델 복잡도(혹은 Serving Cost)의 지표로 삼았다.
- 구체적 계산 예시
- Fully-connected layer: 만약 입력 차원 D_in, 출력 차원 D_out이면, 파라미터 개수가 (D_in×D_out + bias) 정도이고, 곱셈 연산은 대략 D_in×D_out번 일어남(활성함수·Add 연산 등을 제외한 단순 계산).
- MMoE 구성: Experts가 여러 개이므로, Expert별 Hidden Layer 곱셈 + Gate Network 연산도 추가합산.
- 모델 전체: 모든 계층(layer)을 종합해서 한 번 추론 시 수행되는 총 곱셈을 합산한 값을 “Number of Multiplications”로 나타냄.
- 목적
- 동일한 연산량(비슷한 추론 비용)에서 모델 구조만 달리했을 때 성능을 비교하기 위함.
- 모델 크기가 커질수록 서빙 비용이 증가하므로, “비슷한 서빙 비용 대비 어떤 구조가 더 좋은 성능을 내는지”를 보여주는 지표.
정리하면, Table1에서 MMoE(4 experts) vs. Shared-bottom, MMoE(8 experts) vs. Shared-bottom을 동등한 곱셈 연산량 범주에서 비교하기 위해 “Number of Multiplications” 수치를 기록한 것.
Q4. 실험에서 사용된 Metrics
오프라인 지표와 온라인 지표를 나누어 살펴볼 수 있다.
(1) 오프라인 지표
- AUC(Area Under the ROC Curve)
- 논문에서 이진 분류 과제(예: ‘클릭했는가’, ‘좋아요를 눌렀는가’)에 대해 사용.
- Squared Error(MSE)
- 회귀 과제(예: 시청 시간 회귀, 평점 예측 등)에 대해 사용.
주로 이 두 가지를 통해 여러 타스크(Click, Watch Time, Like 등)를 학습 시 평가.
(2) 온라인(라이브) 지표
“YouTube Live Experiment Results”라는 이름으로 A/B 테스트 결과를 보여주는데, 대표적으로 아래 두 부류를 모니터링.
- Engagement Metric
- 사용자 체류 시간(Watch Time) 증가율, 클릭 증가율 등.
- 논문에서는 “시청 시간”이 가장 큰 목표 지표로 자주 언급되었다.
- Satisfaction Metric
- 사용자 만족도를 측정할 수 있는 지표 예)
- (a) “좋아요(Like) 비율”
- (b) 별점이나 유저 설문(5점 만점 중 몇 점인지)
- (c) 비추천(Dismissal)·불만족 지표 등
- 논문 예시로는 “사용자 조사(survey) 응답”을 통해 만족도를 직접 측정하기도 하였다고 언급한다.
- 사용자 만족도를 측정할 수 있는 지표 예)
즉, 오프라인에서는 AUC/MSE로 모델이 해당 행동을 얼마나 잘 예측하는지 객관적 수치를 뽑고,
온라인(A/B 테스트)에서는 실제 사용자들이 추천 리스트에 얼마나 오래 머무르고 만족도가 높은지(Watch Time 및 Likes·설문 등)로 효과를 검증.

